En este proyecto de aprendizaje de Rust hice un scraper para el SIEM. El SIEM contiene datos básicos de miles de establecimientos en México como insumos y productos y algunos datos de contacto. Es una herramienta útil para fomentar el comercio en México. Los datos nos pueden dar también una idea del desarrollo industrial del país.
El proyecto es open source y funciona, pero es muy básico, ya que como comenté arriba lo inicié con el fin de aprender Rust haciendo algo útil.
This may yield a hard-to-catch bug (check missing comma between ‘2’ and ‘3’ in the second assignment:
➜ python3
Python 3.10.6 | packaged by conda-forge | (main, Aug 22 2022, 20:38:29) [Clang 13.0.1 ] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> a = [1, 2 3, 4]
File "<stdin>", line 1
a = [1, 2 3, 4]
^^^
SyntaxError: invalid syntax. Perhaps you forgot a comma?
>>> a = ['1', '2' '3', '4']
>>> a
['1', '23', '4']
>>>
A simple test: one of the most basic Keras examples slightly modified to test the time per epoch and time per step in each of the following configurations. Results below.
Check my language models trained using an automated translation of the STSBenchmark datasets in Spanish and how this improves Sematic Textual Similarity scores.
This is a small framework aimed to make easy the evaluation of Language Models with the STS Benchmark as well as other task-specific evaluation datasets. With it you can compare different models, or versions of the same model improved by fine-tuning. The framework currently use STSBenchmark, the Spanish portion of STS2017 and an example of a custom evaluation dataset.
The framework wraps models from different sources and runs the selected evaluation with them, producing a standarized JSON output.
The main goal of this framework is to help in the evaluation of Language Models for other context-specific tasks.
Evaluation Results on current datasets
Check this notebook for the current results of evaluating several LMs on the standard datasets and in the context-specific example. This results closely resembles the ones published in PapersWithCode and SBERT Pretrained Models
STSBenchmark
STS-es Spanish to Spanish Semantic Textual Similarity
Have a containerized development environment for projects that use some of the most common libraries and utilities for AI, ML, etc. This makes possible to have an independent and upgradable environment that can be shared between projects or server.
This is an initial point that may be adapted to specific needs. Check the Dockerfile to see what will be installed. By default installs GPU support for most libraries as it’s based on GPU enabled Tensorflow image. Packages for R are commented but you can uncomment them.
New software installed in the container will be lost as it runs as a ephemeral container. If you will use it, add to the Dockerfile and rebuild.
Usage
Build the docker image docker build -t ai:latest .
Create or move to you project directory. You may want to create any directory used by the container. It will create them but will be owned by root.
Run the environment:
Use ./denv.sh to run a shell in the environment
Use ./denv_jupyter.sh to run a jupyter notebook server within the environment
Todos sentimos incertidumbre ante la pandemia. Lo primero es la salud de nuestros seres queridos y la nuestra. Hacemos lo que está en nuestras manos para cuidarnos. Y después viene la incertidumbre económica y laboral. En una recesión como la que tememos enfrente aumentan los riesgos para todos. Y muchas personas, desafortunadamente, ya lo están padeciendo.
En una situación así la información es decisiva a comprender y actuar. En OCCMundial lanzamos el Termómetro Laboral para dar a conocer los datos y la información que hemos recopilado y analizado, que consideramos puede ser valiosa para personas y empresas en este momento. Así mismo quiero ampliar aquí algunas de las cosas que hemos encontrado en el grupo de Estrategia de Datos e Inteligencia Artificial hasta la semana del 20 de Abril. Hay que resaltar que esta información toma como base el comportamiento de las empresas que publican con nosotros. En nuestros estudios hemos encontrado que dada nuestra posición como líderes en el mercado de publicación de vacantes en línea en México estos datos son bastante representativos de la actividad laboral general en el país.
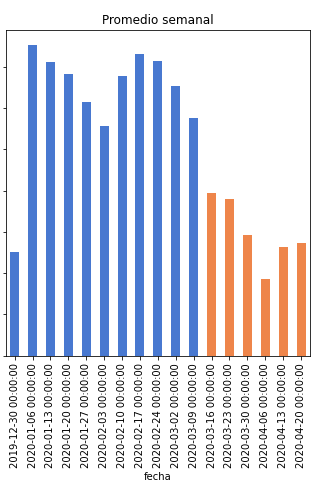
La creación de vacantes nuevas ha caído 54% desde el inicio de la cuarentena
Tomamos como fecha de inicio de la cuarentena el 16 de Marzo, día que en muchas instituciones y empresas comenzamos a hacer home office. El gobierno la comenzó oficialmente hasta una semana después pero los efectos se pudieron ver desde esta semana. Hay que considerar que la semana del 6 de Abril fue la Semana Santa y normalmente se ve una menor actividad. La diferencia en el promedio semanal de vacantes creadas antes y después del inicio de la cuarentena es de 54%.
El tamaño de las barras corresponde a la cantidad de vacantes creadas en cada semana. En azul antes de la cuarentena, en naranja a partir de la cuarentena.
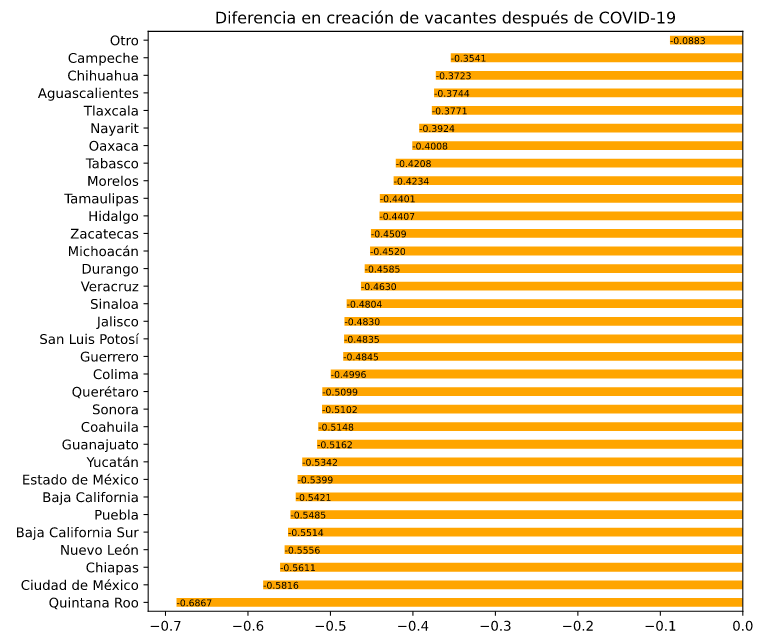
Por estados, es en Quintana Roo donde hay mayor disminución en creación de vacantes, seguido de CDMX, Chiapas y Nuevo León.
El sector turístico parece ser el mas afectado (mas adelante lo podemos ver por categoría y sector), y por lo mismo el estado más afectado es Quintana Roo donde vemos que se han creado en promedio 68% menos vacantes por semana. En la Ciudad de México también ha disminuido mucho la creación de oferta laboral, 58% menos. Nuevo León, Estado de México y Jalisco, los estados en los que normalmente hay una mayor oferta laboral, la creación de vacantes ha disminuido entre 48% y 55%
Diferencia en el promedio semanal de creación de vacantes a raíz de la cuarentena. El renglón “Otro” corresponde a vacantes que no especifican un estado, son en el extranjero.
Aquí vale la pena notar que la ubicación marcada como “Otro” corresponde a vacantes que no especifican un estado en México, o que son en el extranjero. Esto es muchas veces usado por las empresas para especificar que se puede hacer trabajo remoto o home office. De hecho, hemos detectado también un incremento muy grande en las postulaciones de candidatos que buscan opciones de trabajo en casa. Este tipo de vacantes son las que han tenido una menor disminución.
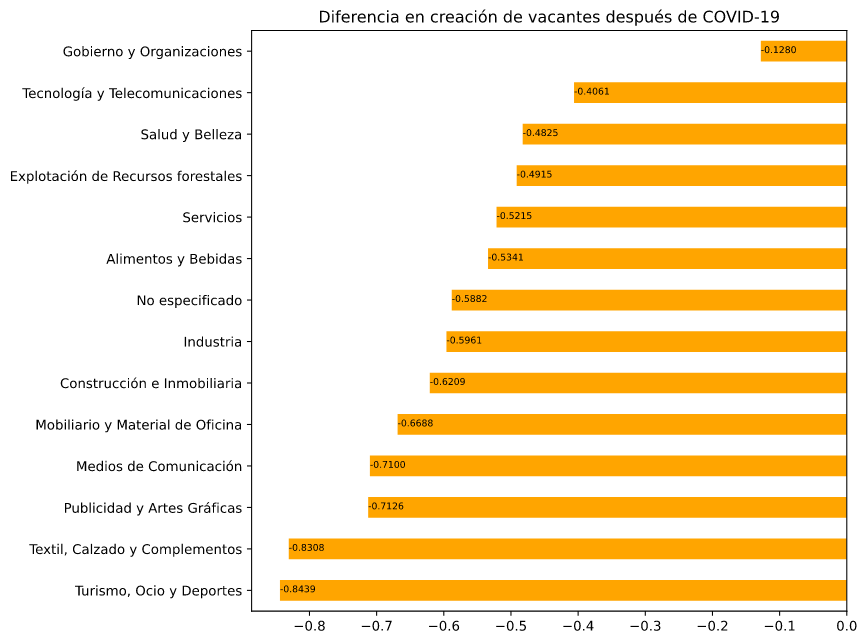
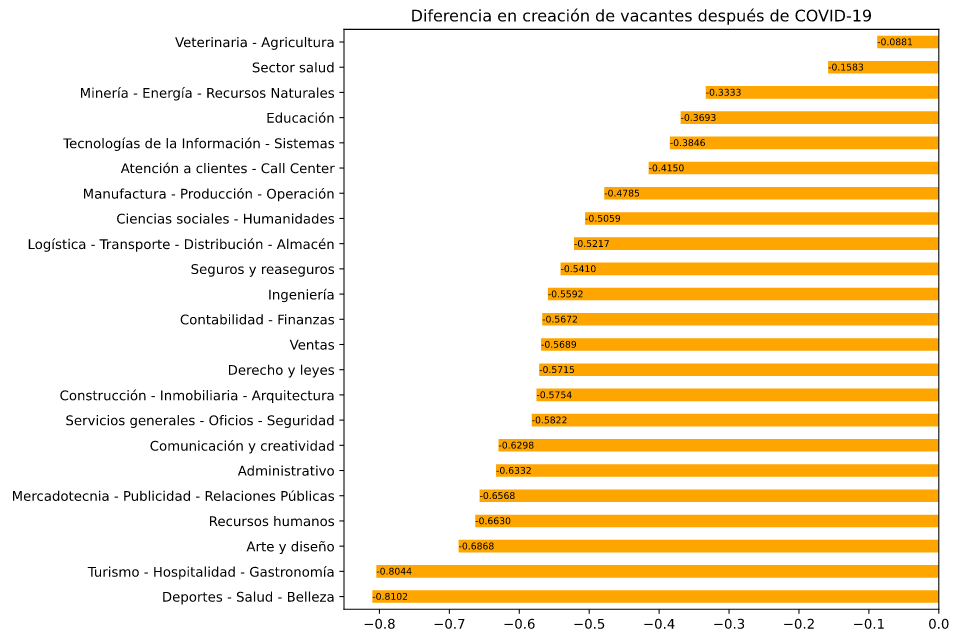
Por sector industrial y categoría de la vacante lo relacionado a turismo es lo mas afectado
En cuanto a sector de las empresas que publican vacantes la mas afectada sin duda es Turismo (han bajado 82% sus contrataciones) y algunos sectores industriales como Calzado y Textiles, y Comunicación y Artes gráficas. En cuanto a categorías de vacante también vemos que las relacionadas a Deportes, Turismo y Arte y diseño han bajado más que otras, como Tecnologías de Información o Salud que presentan menor disminución.
(La diferencia entre Sector Industrial y Categoría de Vacantes es que la primera se refiere al tipo de empresa que está publicando una vacante y la segunda al tipo de trabajo al que se refiere la vacante. Por ejemplo, una vacante en un hotel que busca un gerente administrativo sería sector Turismo y categoría Administrativo)
Esto es a grandes rasgos lo que hemos encontrado en cuanto al cambio en la creación de vacantes desde que inició la cuarentena. Espero que esta información pueda ser de utilidad.
Tratando de ayudar a quien le puedan ser útiles estos datos ya que los formatos en que Secretaría de Salud los ha estado publicando no son los mejores para análisis y visualización.
Los siguientes datos son “semioficiales” ya que son extraídos del mapa de México en el sitio del Sistema Nacional de Vigilancia Epidemiológica. Los datos son almacenados tal como se extraen del mapa y luego son procesados para generar archivos en un formato similar a los publicados en el repositorio de Johns Hopkins.
Reporte diario contiene un archivo CSV por día con los números a la fecha, por estado, con las siguientes columnas:
Casos probables
Casos confirmados
Casos descartados
Fallecimientos
Series de Tiempo contiene archivos CSV con datos agregados en forma de series de tiempo (un día por columna) por cada Estado, para cada una de las categorías:
Series de Tiempo con datos adicionales contiene archivos equivalentes a los mencionados arriba pero con tres días anteriores agregados del repositorio de @wallyqs. Los datos scrapeados por este proyecto los voy a mantener en el directorio original.
Datos originales contiene una copia de los datos tal como fueron extraídos del mapa. La última versión del archivo se guarda con ‘latest’ y las versiones anteriores se pueden acceder mediante commits anteriores. Hasta el 2020-04-05 se guardaba un archivo con timestamp: el nombre es un timestamp del momento de la extracción.
Los datos son extraídos automáticamente 2 veces al día esperando tener los mas actualizados lo antes posible.
Estoy manteniendo este directorio de recursos y datos sobre COVID-19 en México con el fin de apoyar a quienes quieren usarlos para análisis, visualización o simplemente para aprender. Hasta el día de ayer, 13 de Abril, los datos oficiales se estaban publicando en documentos PDF en tablas y en un mapa por estados, lo que dificultaba su aprovechamiento. Se han dado muchos esfuerzos ciudadanos de almacenar, curar y procesar estos datos y es el tipo de información que estoy agregando en este directorio.
Recientemente hemos visto un enorme incremento en el uso de técnicas de Procesamiento de Lenguaje Natural (NLP) pero en los próximos meses y años estaremos viendo su aprovechamiento en tareas y aplicaciones, y su gran potencial será evidente. Como menciona Sebastian Ruder en su blog, estamos viviendo el momento ImageNet de NLP. Parece que cada semana hay uno o varios equipos de investigadores que publican nuevos y mejores Modelos de Lenguaje implementados con deep learning.
Como practicantes de Machine Learning e Inteligencia Artificial nuestro trabajo es crear aplicaciones de “mundo real” considerando tanto los últimos avances en las áreas de investigación como las implicaciones prácticas de su implementación con el fin de resolver necesidades de negocio. Tal vez no usemos el modelo más reciente, o el más grande, o el que actualmente es estado del arte tan pronto como sea publicado en Github o Tensorflow hub, sino que usemos uno que sea mas simple de implementar, más rápido y/o más ligero, y esperemos hasta el momento en que usar uno mas complejo tenga sentido para las tareas específicas de nuestro negocio. Dicho esto, es útil tener un método que nos permita evaluar rápida y fácilmente modelos para nuestras tareas específicas. Además algunos de los resultados de esas evaluaciones se pueden considerar guías generales del desempeño de los modelos, con la esperanza de que puedan ser generalizados a otras tareas.
He estado trabajando en un método como el descrito arriba y quiero compartir algunos resultados que he encontrado de la comparación de varios Modelos Neuronales de Lenguaje que Google ha puesto a disposición de la comunidad en Tensorflow Hub. Hay pocos recursos disponibles en español en comparación a otros idiomas por lo que espero que esto contribuya a quien lo pueda necesitar. Los resultados más importantes que he encontrado son:
Los modelos NNLM entrenados en español tienen un mejor desempeño que los mismos modelos entrenados en inglés.
La versión normalizada de estos modelos tiene un mejor desempeño que los modelos no normalizados.
En general los modelos de 50 y 128 dimensiones tienen un desempeño similar. Sin embargo parece que la optimización de hiperparámetros puede beneficiar más al modelo de 128 dimensiones.
Todos los detalles y resultados están disponibles en este repositorio de Github. Espero poder agregar a la comparación otros modelos mas recientes basados en Transformers próximamente.